

Este tipo de problema sempre surge e confunde as pessoas. Consegue resolver? O operador A faz um trabalho em 6 semanas. O operador B, faz em 9 semanas. Quanto tempo vão levar se fizerem juntos? Resposta. Hipótese: Estamos assumindo que é possível somar o trabalho de ambos sem prejuízo. E este tipo de problema é …
Categoria: ForgottenMath
O problema da razão inversa
Este tipo de problema sempre surge e confunde as pessoas. Consegue resolver? O operador A faz um trabalho em 6 semanas. O operador B, faz em 9 semanas. Quanto tempo vão levar se fizerem juntos? Resposta no próximo post. O Compêndio de Ideias do Prof. Arnaldo: https://asgunzi.github.io/Compendium/ Trilha Sonora: Epitáfio - Titãs Uma belíssima música …
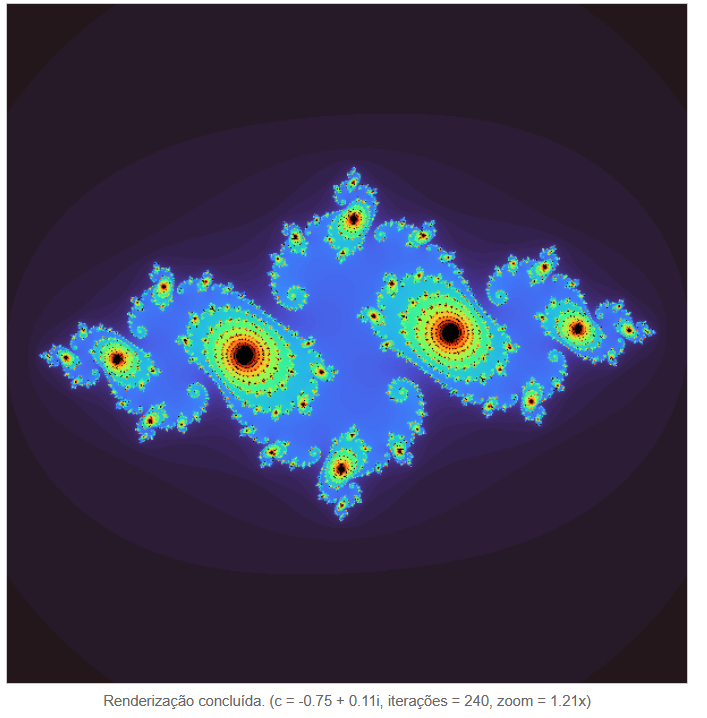
Fractais de Julia
Mexa interativamente nos fractais de Julia. Criei uma versãozinha interativa em Javascript: https://asgunzi.neocities.org/ArteMatematica/Julia Fractais são formas autossimilares e que se repetem infinitamente. Esses fractais têm este nome em homenagem ao matemático Gaston Júlia, que os estudou. São baseados na fórmula zₙ₊₁ = zₙ² + c No plano complexo, ou seja, têm uma parte real e …

O círculo de tangentes
Como criar um círculo apenas com retas? Com matemática, é claro. A construção acima é formada apenas com retas. Imagine duas retas verticais, uma no x1 = 0 e outra no x2 = 1. As primeiras retas horizontais ligam o y1 = 1 a y2 =1 e a mesma coisa para y1 = -1 e …
Quantas figurinhas da Copa 2026 preciso comprar?
Vi um vídeo do governador de São Paulo, Tarcísio de Freitas, calculando o número de figurinhas a comprar. https://www.instagram.com/reel/DZ2HvdrRE66/?igsh=ZzI4Mm01eWNseDdz Achei impreciso, porque ele dá a entender que 7311 figurinhas fornece uma certeza de completar o álbum, e não uma probabilidade. E também o vídeo é muito rápido, editado para o formato do Instagram. Fiz umas …
Continue lendo Quantas figurinhas da Copa 2026 preciso comprar?

Resposta dos números ocultos
Formulação. Arnaldo escolhe um inteiro a, a>=0, e Bernardo escolhe um inteiro b, b>=0. Ambos dizem o número, em segredo à Carla. Ela escreve em um quadro os números 5, 8 e 15, sendo um desses a soma a+b. Carla toca uma campainha e Arnaldo e Bernardo, individualmente, escrevem em papéis se sabem ou não …

Puzzle da soma dos números
Arnaldo escolhe um inteiro a, a>=0, e Bernardo escolhe um inteiro b, b>=0. Ambos dizem o número, em segredo à Carla. Ela escreve em um quadro os números 5, 8 e 15, sendo um desses a soma a+b. Carla toca uma campainha e Arnaldo e Bernardo, individualmente, escrevem em papéis se sabem ou não qual …
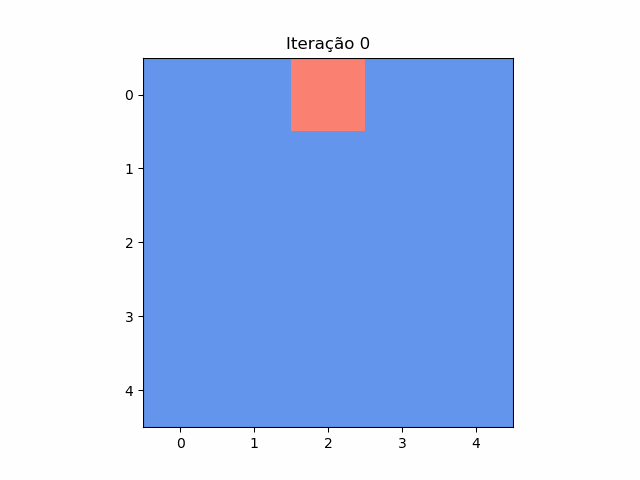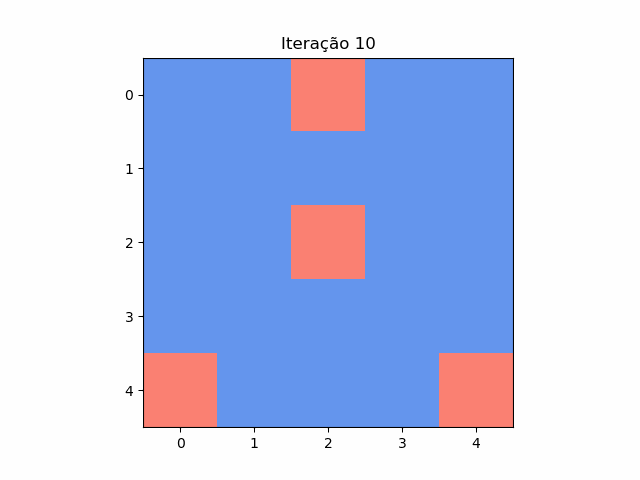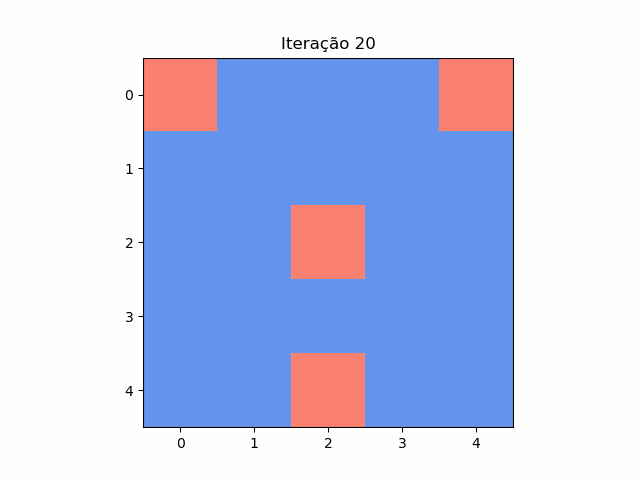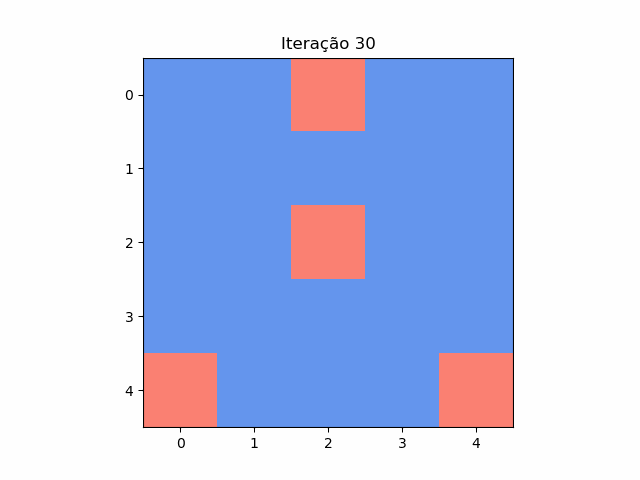
Resposta do puzzle das casas
Em cada casa de um tabuleiro 5x5 está escrito 1 ou -1. Em cada passo, troca-se o número de cada uma das 25 casas pelo resultado da multiplicação dos números de suas casas vizinhas (são vizinhas se tiverem um lado em comum). Posição inicial: [[ 1 1 -1 1 1][ 1 1 1 1 1][ …
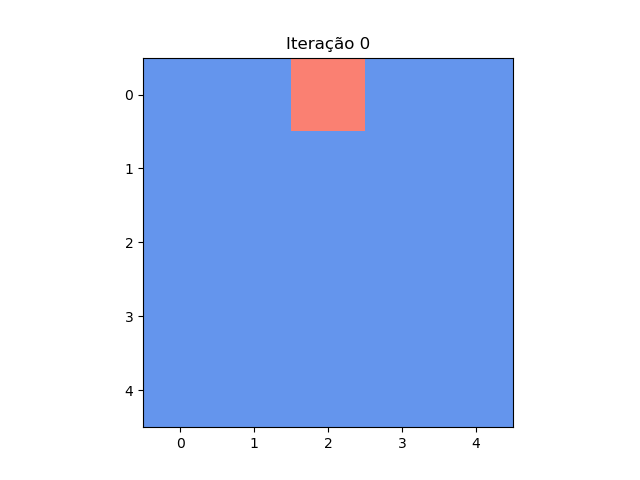
Puzzle das casas
Em cada casa de um tabuleiro 5x5 está escrito 1 ou -1. Em cada passo, troca-se o número de cada uma das 25 casas pelo resultado da multiplicação dos números de suas casas vizinhas (são vizinhas se tiverem um lado em comum). Posição inicial: [[ 1 1 -1 1 1][ 1 1 1 1 1][ …
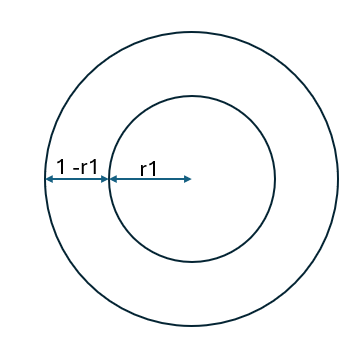
Resposta do Puzzle do lago
Você está no meio de um lago exatamente circular. Na borda do lado, há uma bruxa malvada que ter te transformar em um sapo e depois arrancar e comer suas pernas. Ela é quatro vezes mais rápida que o seu barquinho no lago, porém, se você alcançar a margem em segurança, consegue correr mais rápido …
Resposta – Puzzle das bolinhas de gude
Você tem dois potes e 100 bolinhas de gude. Metade das bolinhas é vermelha e metade é azul. Um demônio escolherá um dos potes e irá sortear uma bolinha. Se ele escolher a bolinha azul, você ganhará uma vida próspera e tranquila; senão, ele irá enviar uma horda infinita de pernilongos para te atanazar. A …

Puzzle das bolinhas de gude
Você tem dois potes e 100 bolinhas de gude. Metade das bolinhas é vermelha e metade é azul. Um demônio escolherá um dos potes e irá sortear uma bolinha. Se ele escolher a bolinha azul, você ganhará uma vida próspera e tranquila; senão, ele irá enviar uma horda infinita de pernilongos para te atanazar. A …

Você precisa fazer login para comentar.