

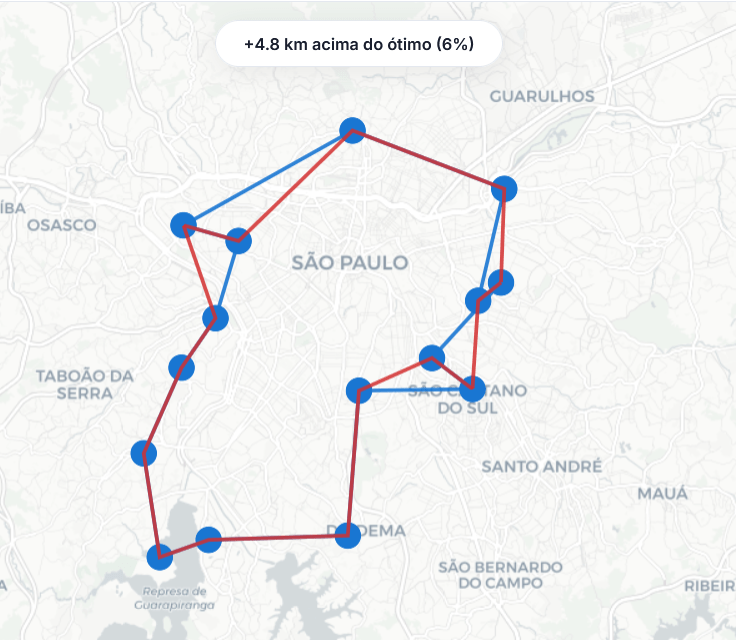
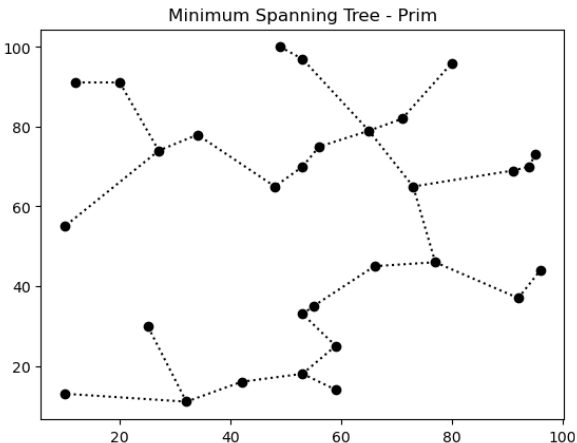
Fiz um joguinho para ilustrar o problema do Caixeiro-Viajante. Confira aqui. Você começa com 15 pontos aleatórios. O objetivo é percorrer todos os pontos, com o menor deslocamento total possível, numa rota fechada. Ao clicar nos pontos, eles ficam azuis, indicando uma rota já percorrida. Ao final, o joguinho te dá a rota ótima e …






Você precisa fazer login para comentar.