

Numa ocasião, estive a apresentar um modelo de planejamento da produção que desenvolvi no passado. Era um modelo de programação linear inteira mista, horizonte de 18 meses, que balanceava demanda, produção e estoques. Uma pessoa do público fez uma pergunta. Era algo assim: "O seu modelo é determinístico, mas o mundo pode mudar, há uma …
Tag: Analytics
Os melhores trabalhos são óbvios
Os melhores insights são os óbvios. Porém, o insight é óbvio a posteriori. A priori sempre há muito ruído, muitas hipóteses alternativas, interesses de vários lados, falta de clareza, etc. A posteriori sim, aí fica evidente ver o que funciona e o que não funciona. Aquilo que funciona e é simples parece muito fácil a …

A tara por código
Quer ouvir um segredo? Saber código não faz de você um bom Data Scientist. Conceito >>> Ferramenta. Sempre. Linguagens e Frameworks vêm e vão. Surge algo novo todo santo dia. Fundamentos ficam Código sem conceito é como um castelo de areia Modelagem é arte: Um modelo é, necessariamente, uma simplificação da realidade, infinitamente mais complexa. …

Aulinha sobre Pesquisa Operacional
Aulinha sobre Pesquisa Operacional na prática, na disciplina de Tecnologia para Suporte à Gestão do Programa Avançado em Transformação Digital do Insper. A ideia foi apresentar projetos de Otimização e Machine Learning, tanto no Mercado Livre quanto em experiências passadas. Alguns dos tópicos: - Cases ilustrando o poder de métodos analíticos aplicados - O tipo …

Desafio das balas
O professor trouxe à turma uma quantidade de balas, porém, só distribuirá se eles conseguirem adivinhar o número de balas. Ele dá algumas dicas: Quando divido de três em três, sobram duas balas Quando divido de cinco em cinco, sobram três balas Quando divido de sete em sete, sobram duas balas Ajude a nossa turma …
O problema da secretária – Solução
Formulação:Imagine que você está entrevistando candidatos para um emprego de secretária, e quer contratar o melhor possível. Há algumas regras adicionais, em relação a um processo comum: você só pode entrevistar um candidato por vez, deve tomar uma decisão imediatamente após a entrevista e não pode voltar atrás em uma decisão já tomada. Se rejeitar …

O jogo do Bandido de Múltiplos braços
Segue no link uma implementação lúdica, do problema do bandido de múltiplos braços. https://asgunzi.neocities.org/ArteMatematica/bandido O “one-armed bandit” é um caça-níqueis comum, chamado assim porque tem um braço só, e porque é um ladrão de recursos. Você está em um cassino com N caça-níqueis (daí o termo, multi-armed bandit). Cada máquina tem uma probabilidade de recompensa …
P-Hacking
Testes de Hipóteses, com o seu famoso p-value, são métodos extremamente científicos e embasados estatisticamente para chegar a conclusões robustas, certo? Nem tanto. Há uma prática chamada p-hacking, que significa “hackear o p-value”. Há um incentivo para que autores publiquem artigos, e para artigos serem publicados, os dados devem ter validade estatística. Para tal, é …
Três histórias do que não fazer em suas análises
Não despreze o conhecimento do negócio Uma das analistas do time estava estudando se os descontos estavam impulsionando vendas, uma típica análise de elasticidade preço-demanda, num certo negócio. Ela comentou os descontos estavam na ordem de R$ 10 bilhões. Retruquei na hora que tinha alguma coisa muito errada nos números. Porque o faturamento desta unidade …
Continue lendo Três histórias do que não fazer em suas análises
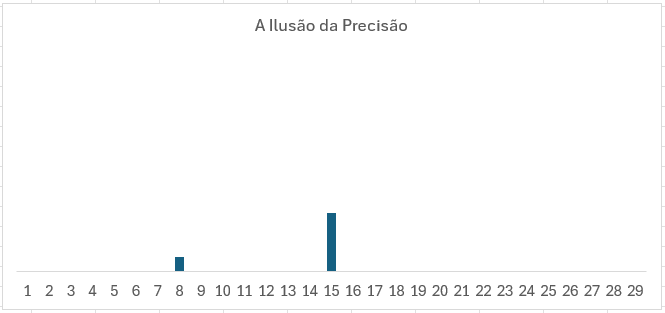
A Ilusão da Precisão
Um erro que o analista júnior (e uns seniores também) vai cometer é a "Ilusão da Precisão". Digamos que quer fazer um forecast. Aparentemente, fazer em nível SKU é mais preciso e útil do que a nível grupo de produto ou categoria geral, que são bem mais agregados. Porém, o nosso herói vai se deparar, …

Retrospectiva 2024 – Parte 1
Alguns dos melhores trabalhos do time de Projetos Analíticos em 2024 incluem:EUDR - Criamos o K-Tracking, um protótipo de ferramenta para rastreabilidade de madeira para atender as exigências do regulamento europeu sobre desmatamento, EUDR.SequenCel: Ferramenta de otimização para sequenciamento de celulose Fluff, diminuindo setups de máquinas e garantindo um melhor atendimento de clientes.No Projeto Figueira, …
Algumas reflexões sobre IA
As reflexões abaixo são fruto de conferência que participei recentemente + conversas com colegas diversos. Casos de sucesso e Analytics tradicional Foram citados alguns casos de sucesso das empresas: algoritmos para S&OP (forecasts e planejamento de produção). Apoio para refatorar código. Estudo para precificação de contratos. Manutenção preditiva em caixas telefônicas, entre outros. O que …

Você precisa fazer login para comentar.