

Dan Ariely é um palestrante internacionalmente conhecido, autor de best seller sobre economia comportamental, figura carimbada em TED talks e tem até série na Netflix. Há alguns dias, pesquisadores investigativos publicaram evidências fortes de que um de seus estudos é fruto de fraude.

Como o autor de “A (honesta) verdade sobre a desonestidade” pode ter ele mesmo fabricado dados e conclusões? Ele e os demais envolvidos afirmam que também não sabiam da manipulação.
Independente ou não de má fé, sua imagem fica extremamente arranhada.
Vale muito a pena entender a análise investigativa completa. Foi um trabalho de “Sherlock Holmes” de informação, publicado no blog Data Colada: https://datacolada.org/98
Segue um resumo:
- A tese de Ariely é de que assinar formulários prometendo honestidade antes de preencher os dados faz as pessoas serem mais honestas do que assinar só no final.
- Essa tese levou diversos governos e empresas a mudarem seus formulários. O problema é que a conclusão não conseguiu ser replicada em estudos similares, o que levou os próprios autores a alertarem sobre o fato, e publicarem os dados crus do estudo original, de 2012.
- Os dados originais eram de uma seguradora, e os clientes informavam a milhagem dos carros segurados (13.488 registros).
- Uma distribuição comum de milhagem segue uma normal, já a distribuição de parte dos dados era mais parecida com uma uniforme, que pode ser facilmente gerada com um ‘randbetween’ do Excel.
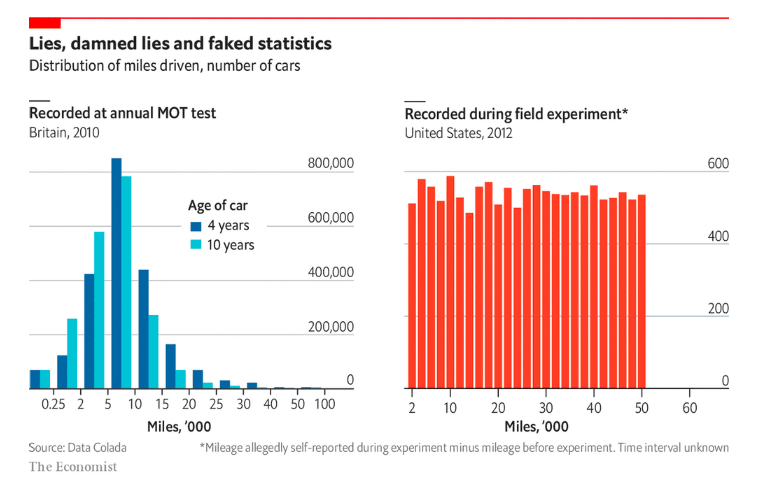
- Todos os carros que apresentavam distribuição uniforme tinham valor abaixo de 50.000 milhas – o valor máximo foi 49.997. É extremamente implausível que uma distribuição até 50 mil tenha alta frequência, e não haja nenhum valor maior (ou seja, foi algo como um ‘randbetween 50.000’). Os investigadores também garantem que não teve um corte para gerar o gráfico, são os dados brutos que estão estranhos mesmo.
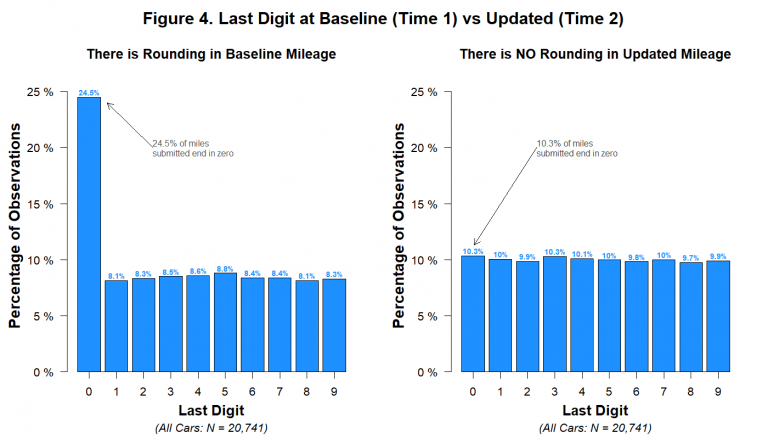
- Quando uma pessoa preenche um formulário desses, ou ela realmente consulta o odômetro e anota certinho, ou dá uma arrendondada de cabeça. A frequência de números arredondados, terminando em zero, tende a ser maior. Nas bases do próprio estudo, uma base realmente tinha maior frequência em números terminando em 0. Porém, outra base tinha igual frequência em todos os dígitos (de novo, o randbetween é uma explicação fácil).
- A fonte utilizada na tabela estava diferente, como explica este resumo da revista The Economist, baseada no artigo.
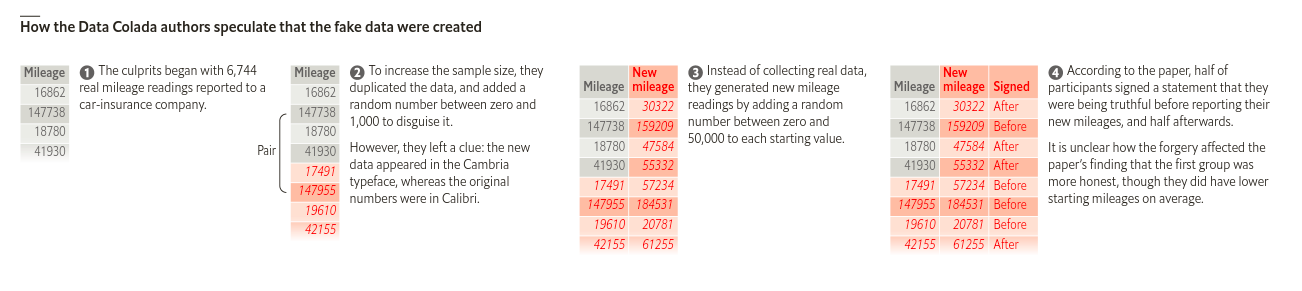
Não dá para afirmar que Ariely propositalmente manipulou dados, mas algo que ele deveria ter feito, minimamente, era analisar a consistência dos mesmos.
Algumas lições, para quem trabalha com dados:
1) Nunca, de forma alguma, crie informações falsas.
2) Tenha sempre as bases de dados e o racional auditáveis.
3) Conheça bem as informações que tem, faça checagens de consistência.
Por fim, uma ótima reflexão de Sílvio Meira. Os dados não são o “novo petróleo”. Estão mais para “novo urânio”. Isso porque os dados devem ser tratados, refinados, e atingir massa crítica para gerar valor, e o descarte é um perigo, para o negócio e para o ecossistema.
Links:

Republicou isso em Ferramentas em Excel-Vba.
CurtirCurtir
Republicou isso em Thiagoteca.
CurtirCurtido por 1 pessoa