
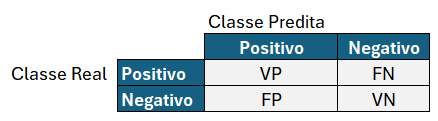
Os termos citados acima são algumas das métricas utilizadas para avaliar modelos de machine learning, dentro do contexto de um classificador.
São muitas, são confusas, e por isso mesmo, vale um post explicando a necessidade delas. Para introduzir o tema, nada melhor que Machado de Assis!

No conto “O Alienista”, o médico Simão Bacamarte funda um hospício chamado Casa Verde, na cidade de Itaguaí. O médico queria identificar e internar os loucos, só que acabou prendendo a cidade inteira.
Para efeito ilustrativo, digamos que a cidade tivesse 1000 pessoas à época de Machado de Assis, e que 10 fossem loucos de verdade. Pelo método de Bacamarte, todos os 10 loucos realmente seriam internados, ao passo que os 990 restantes também o seriam.
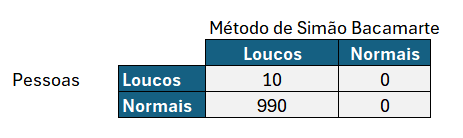
Imagine que você pergunta ao médico se o que ele está fazendo não seria um exagero, e ele responde que a Precisão, utilizada em machine learning, é dada pela taxa de verdadeiros positivos divididos por verdadeiro positivo + falso negativo, e a precisão do método dele é de 100%!
Precisão = VP / (VP + FN) = 10 / (10 +0) = 100%
(Detalharemos a fórmula nos tópicos abaixo).
Como vamos argumentar contra uma fórmula? Ora, argumentamos com outra fórmula…
Especificidade = VN / (VN + FP) = 0 / (0 + 990) = 0%
Realmente o teste utilizado deu uma Precisão bem alta (todos os verdadeiros loucos foram presos), mas a Especificidade foi bem horrível, porque não houve verdadeiros negativos, já que o número de não loucos internados foi a cidade toda!
O que é um Classificador?
Um classificador é um modelo que, conforme o próprio nome indica, classifica: recebe uma série de features como input e fornece a classe na saída. No caso do Alienista, as classes eram louco e não louco.
Num contexto mais de negócios, digamos, eu tenho uma cadeia de loja de roupas, e quero avaliar se as pessoas que entram lá vão ou não comprar. O que sei delas? Digamos que eu saiba algumas características: sexo, idade aproximada, localização da loja e horário do dia. Com base nisso, e com um histórico de dados, conseguirei criar um modelo que vai predizer se um cliente novo que entrar em uma das lojas, em determinado horário, vai ou não comprar. Se vai mesmo comprar ou não depende de uma série de fatores outros, mas na média, e para ajudar na tomada de decisão, o modelo vai mais acertar do que errar (pelo menos essa é a intenção).
E como saber se o modelo é bom mesmo, ou é um modelo que chuta qualquer coisa, tal como no conto introdutório? Bom, é para isso que servem as avaliações acima.
O que são Falsos positivos, falsos negativos
Outro conceito importante é saber o que são os falsos e verdadeiros positivos, e falsos e verdadeiros negativos.
Para entender o “positivo”, imagine um teste de gravidez: se a mulher fez o teste e deu positivo, quer dizer que ela está grávida! No contexto da loja de roupas, o “positivo” pode ser o cliente comprar, e o “negativo” é o cliente entrar na loja, ficar passeando e sair sem nada adquirir…
Note que o cliente pode comprar ou não, e o modelo pode predizer que ele vai comprar ou não. Ou seja, há quatro possibilidades, que podem ser expressas utilizando uma “matriz de confusão”, que como o próprio nome indica, é confusa mesmo!

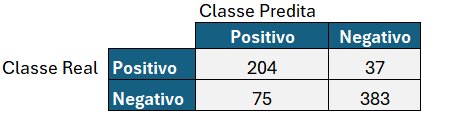
Digamos que a matriz de confusão para o caso da loja de roupas seja:
Um Verdadeiro Positivo (VP) é o caso em que o cliente realmente comprou, e o modelo tinha predito que ele compraria.
Um Falso Positivo (FP) é o caso em que o cliente NÃO comprou na realidade, e o modelo tinha predito que ele compraria. Imagine o “Falso” como um sinal negativo, então um falso positivo é, na verdade, um negativo.
Os casos negativos são análogos, ao contrário.
Um Verdadeiro Negativo (VN) é o caso em que o cliente NÃO comprou na realidade, e o modelo tinha predito que ele NÃO compraria.
Um Falso Negativo (FN) é o caso em que o cliente comprou na realidade, e o modelo tinha predito que ele NÃO compraria. Imagine o “Falso” como um sinal negativo, então um falso negativo é, na verdade, um positivo.
Os casos que os modelos coincidem com o resultado são fáceis de entender, então vamos utilizar um meme para ilustrar os casos de falso positivo e falso negativo.

Acurácia, precisão, recall…
E é neste ponto que entram os termos citados no início.
A Acurácia é um indicador geral de como o modelo se comporta. Em termos gerais, indica o quanto ele acerta como um todo.
Acurácia é Soma dos elementos da diagonal principal / Soma de todos elementos.
Acurácia = (VP + VN) / Total
Acurácia= (204+383)/(204 + 37 + 75 + 383)=83,98%
Se só tiver que olhar para um número, a acurácia é a mais importante.
Já a Sensitividade e Especificidade focam nos positivos e nos negativos. É como se fosse um detalhamento da análise, para melhor entender o modelo.
Sensitividade – A Sensitividade (ou Precisão) responde a seguinte pergunta: de todas as observações da classe “Positivo” na vida real, quantas o algoritmo classificou como “Positivo”?
Sensitividade = VP / (VP + FN)
Ver a fórmula é meio chata, mas imagine que ela olha para quantos casos positivos o modelo acertou, em relação a todos os positivos reais.
Em geral, quero saber o quanto o modelo é bom em relação à vida real, então as predições do modelo vão no numerador, e o número de casos reais, no denominador. Note que VP + FN = total de positivos reais.
Sensitividade= 204 / (204 + 37) = 84,65%
A Especificidade (ou Recall) é o contrário, basicamente olhando para a classe “Negativo”.
A Especificidade responde a seguinte pergunta: de todas as observações da classe “Negativo”, quantas o algoritmo classificou como “Negativo”?
Especificidade = VN / (VN + FP)
Especificidade=383/(75+383)=83,62%
Novamente, a predição do modelo vai no numerador, e o número de casos reais, no denominador. Note que VN + FP = total de negativos reais.
A motivação para essas métricas todas é que o modelo pode estar desequilibrado, priorizando a detecção de positivos ou de negativos, como no caso do Alienista. Aí, uma das métricas será boa, já a outra, não.
—
E esse tal de F1 score?
Para dar mais uma complicada, existe mais outro indicador, o F1 score. Esta é uma média harmônica da sensitividade e especificidade (ou precisão e recall). Sendo uma média, é possível também ponderar esta média segundo pesos arbitrários.
F1 Score = 2*sensitividade*especificidade/(sensitividade+especificidade)
A fórmula a seguir é a mesma coisa:

A ideia aqui é representar ambas características com um número, ponderando segundo algum fator que faça sentido para o negócio.
—
Curva ROC
A palavra ROC significa Receiver Operating Characteristics (ROC). É uma curva que tem a Especificidade no eixo Y e a taxa de Falsos Positivos no eixo X.
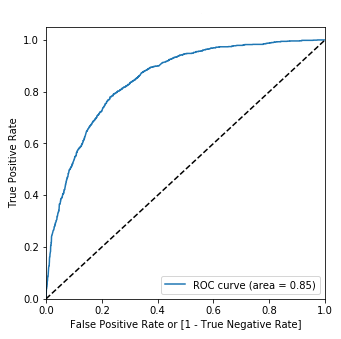
Eixo Y: Sensitividade = VP / (VP + FN)
Eixo X: Taxa de Falsos Positivos = FP / (FP + VN)
A curva que representa as taxas de Sensitividade para diversas Taxas de Falso Positivo é a curva ROC.
Este tipo de análise é particularmente útil quando é possível mudar parâmetros do modelo para considerar diversas faixas de falsos positivos. Um caso assim é o de regressão logística, onde o output é um valor de probabilidade de pertencimento a uma das classes.
Na curva ROC, o classificador ideal é aquele onde a sensitividade é 100% para todos os valores do eixo X, portanto, é uma curva em 1. Como regra de bolso, quanto mais próximo de 1, melhor.
Finalmente, um último conceito. A área debaixo da curva (AUC) serve para transformar um gráfico, a curva ROC, em um número. Isso porque gráficos são bonitos de ver, mas ruins para exprimir um valor numérico objetivo para comparação com outros modelos.
Bom, com todas essas explicações, espero que fique claro como podemos fazer para distinguir um bom de um mal modelo de classificação, tal como o modelo do Alienista, no início do texto!
